
15小时 几千元训完中文版LLaMA2!大模型的门槛降低了
现在,15小时、几千块钱、85亿 token数据,即可训出中文LLaMA2。方案完全开源,包括全套训练流程、代码及权重,而且无商业限制,还可迁移应用到任意垂类领域和从头预训练大模型的低成本构建。要知道,在以前从头预训练大模型此前被戏称“要5000万美元才能入局”。

LLaMA-2模型
性能表现良好
Colossal-LLaMA-2在多个榜单上进行了评测,具体表现如下:
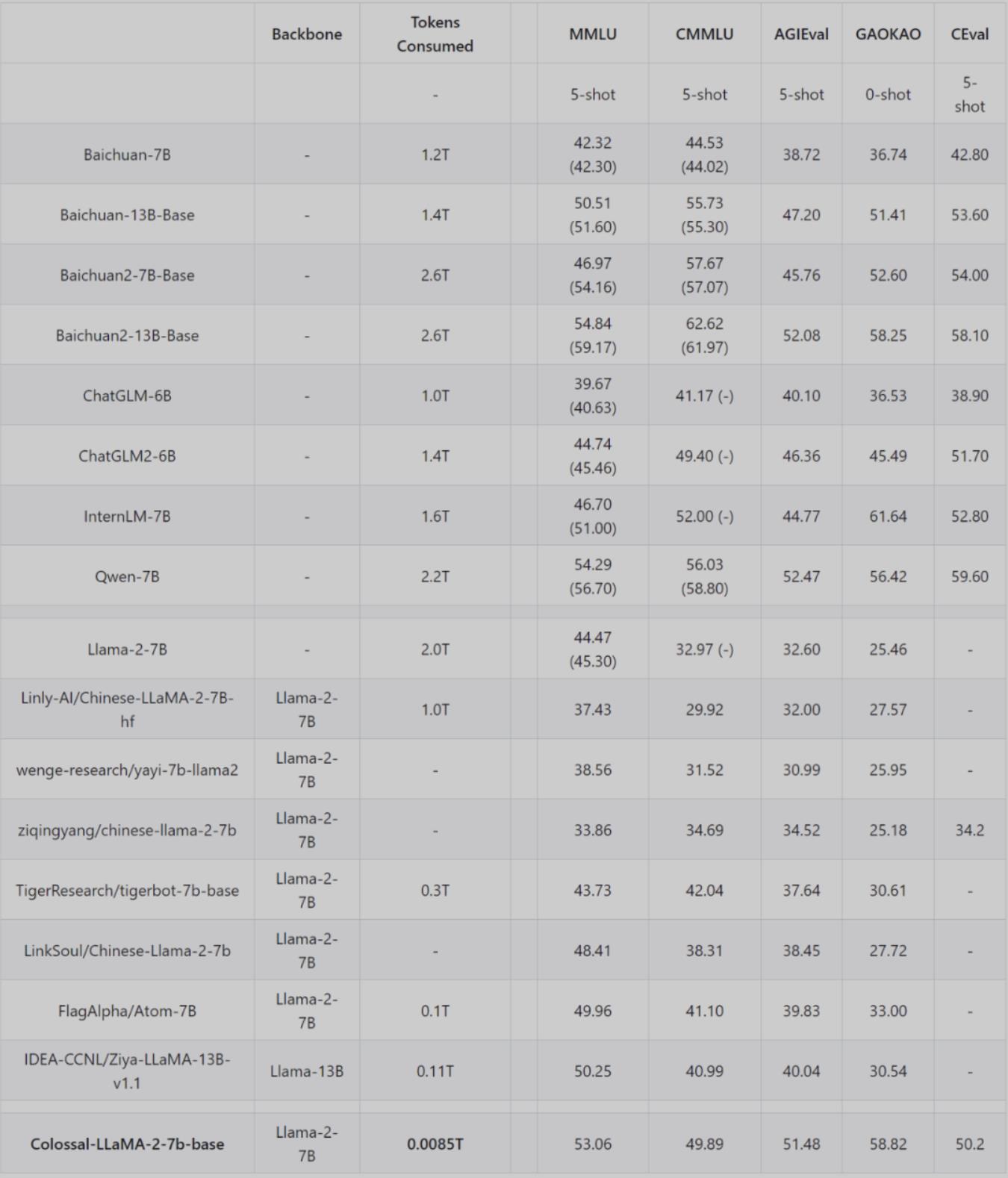
基于ColossalEval评分,括号中分数来源于对应模型官方发布的榜单分数,C-Eval 分数来源于官网 Leaderboard。
在英文MMLU榜单中,Colossal-LLaMA-2-7B-base在低成本增量预训练的加持下,克服了灾难性遗忘的问题,能力逐步提升(44.47 -> 53.06),在所有 7B 规模的模型中,表现优异。
中文榜单方面主要对比了CMMLU、 AGIEVAL、GAOKAO 和 C-Eval,效果远好于LLaMA-2 的其他中文汉化模型。甚至表现超过了一些使用中文语料从头训练大模型(成本花费或上千万)。尤其是和原始LLaMA-2 相比,在中文能力上有了质的飞跃 (CMMLU: 32.97 -> 49.89)。
而通过SFT、LoRA等方式微调,能有效注入基座模型的知识与能力十分有限,不能很好满足高质量领域知识或垂类模型应用的构建的需求。
本文由小熊AI网发布,不代表小熊AI网立场,转载联系作者并注明出处:https://www.xiaoxiong360.com/html/software/792.html