
Audio2Facer技术:用声音生成步唇面部表情动作
Audio2Face是一种基于深度学习的技术,它可以将音频数据转换为面部动画,从而实现从声音到面部表情的转换。该技术是由浙江大学和网易伏羲AI实验室联合开发的。
Audio2Face技术采用了端到端的机器学习框架,它可以接受音频信号作为输入,并生成相应的面部动画。这个过程包括:语音特征提取、语音到面部特征的转换,以及面部特征到面部动画的生成。
当我们现在用该技术将声音去驱动虚拟人的时候,你就会发现虚拟人也可以做到“有情感”,不再像单纯文本驱动时显得那么僵硬。
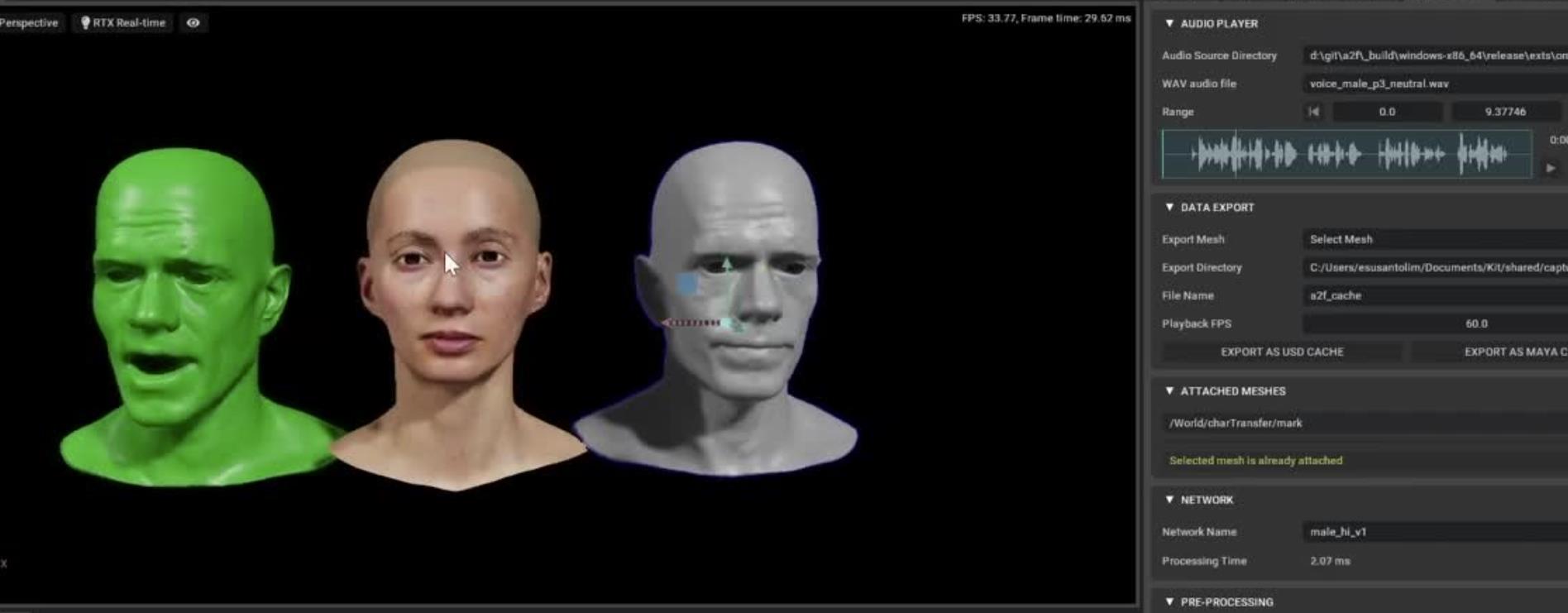
Audio2Face技术
step1:语音特征提取
在语音特征提取阶段,Audio2Face技术使用语音合成技术将音频数据转化为文本,再利用语音识别技术将文本转化成语音特征向量。这个过程中使用了循环神经网络(RNN)和长短时记忆网络(LSTM)等深度学习算法进行建模。
step2:语音到面部特征的转换
在语音到面部特征转换阶段,Audio2Face技术利用已训练好的神经网络模型将语音特征向量转换成面部特征向量。这个过程中采用了卷积神经网络(CNN)和变换器(Transformer)等深度学习架构进行建模。
step3:在面部特征到面部动画生成阶段
最后,在面部特征到面部动画生成阶段,Audio2Face技术利用预先训练好的表情合成模型将面部特征向量转换成面部动画。这个过程中采用了基于图像的建模技术和面部动画参数合成算法等技术进行建模。
Audio2Face技术的优点在于它可以直接从音频数据中生成实时的面部动画,不需要任何手动调整。此外,该技术还支持多种音调和说话风格的调节,可以适应不同的场景和应用需求。
所以,Audio2Face技术是一种将音频数据转化为面部动画的重要工具,它让数字虚拟人更加的真实,更加的自然,具有很高的实用价值和应用价值。
本文由小熊AI网发布,不代表小熊AI网立场,转载联系作者并注明出处:https://www.xiaoxiong360.com/html/software/480.html