
清华&NUS发布成果:通过简单对话,让大模型自动标注图像
多模态大模型集成了检测分割模块后,抠图变得更加简单!只需用自然语言描述需求,模型就能快速标注出要寻找的物体,并给出文字解释。这一全新多模态大模型是由新加坡国立大学NExT++实验室与清华刘知远团队共同打造的。

随着GPT-4v的推出,多模态领域涌现出许多新模型,如LLaVA、BLIP-2等。为了进一步扩展多模态大模型的区域理解能力,研究团队开发了一个能够同时进行对话和检测、分割的多模态模型NExT-Chat。
NExT-Chat的最大亮点是在多模态模型中引入了位置输入和输出的能力。其中,位置输入能力指的是根据指定的区域回答问题;位置输出能力则是指定位对话中提及的物体。
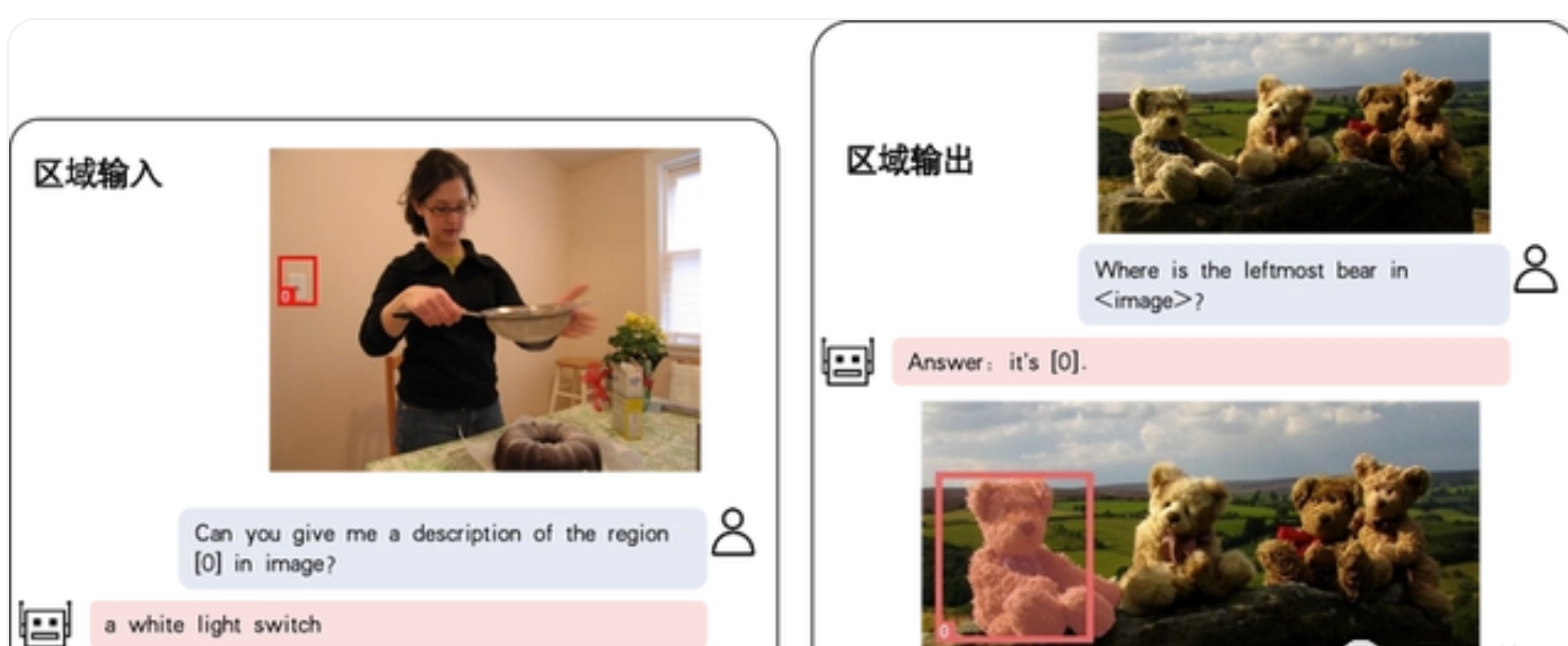
即使是复杂的定位问题,NExT-Chat也能迎刃而解。除了物体定位,NExT-Chat还可以对图片或其中的某个部分进行描述。分析完图像的内容之后,NExT-Chat可以利用得到的信息进行推理。
为了准确评估NExT-Chat的表现,研究团队在多个任务数据集上进行了测试,并在多个数据集上取得了SOTA(State-of-the-Art)结果。作者首先展示了NExT-Chat在指代表达式分割(RES)任务上的实验结果。尽管只使用了极少量的分割数据,NExT-Chat展现出了良好的指代分割能力,甚至超过了一系列的有监督模型(如MCN、VLT等)以及使用了5倍以上分割掩模标注的LISA方法。
接下来,研究团队展示了NExT-Chat在REC任务上的实验结果。如下表所示,相比于相当一系列的有监督方法(如UNITER),NExT-Chat都能够取得更优的效果。一个有趣的发现是,NExT-Chat比使用了类似框训练数据的Shikra效果稍差一些。作者猜测,这是由于pix2emb方法中LM loss和detection loss更难以平衡,以及Shikra更贴近现有的纯文本大模型的预训练形式所导致的。
本文由小熊AI网发布,不代表小熊AI网立场,转载联系作者并注明出处:https://www.xiaoxiong360.com/html/software/2575.html